
Le misure di variabilità sono utilizzate per descrivere il grado di variabilità delle osservazioni rispetto ad un indice di tendenza centrale.
In altri termini, le misure di variabilità consentono di valutare la dispersione dei dati attorno ad un valore centrale, che può essere rappresentato ad esempio dalla media o dalla mediana. Esse forniscono informazioni preziose sulla distribuzione dei dati, permettendo di ottenere una migliore comprensione del fenomeno osservato.
Le tecniche per misurare la variabilità di insiemi di dati sono numerose.
Tra queste, le più note (e più utilizzate) sono:
- il campo di variabilità
- lo scarto medio e la varianza
- lo scarto quadratico medio o deviazione standard
- il coefficiente di variazione
Visualizzeremo graficamente i concetti acquisiti di tendenza centrale e dispersione ritornando a parlare di asimmetria e introducendo il concetto di curtosi.
Il campo di variabilità (o gamma)
Il campo di variabilità, o Gamma (o range, per gli anglosassoni), è dato dalla differenza fra il valore massimo e quello minimo dei dati non raggruppati di una distribuzione di frequenza.
Si tratta di un calcolo velocissimo, che in R può essere computato così:
max(var) - min(var)
In realtà il massimo e il minimo sono visualizzabili anche con:
range(var)
e compaiono come primo e ultimo termine in:
fivenum(var)
Per dati raggruppati, il campo di range è definito come la differenza tra il confine superiore della classe massima e il confine inferiore della classe minima.
Un campo di variabilità modificato è un campo dal quale è stata eliminata una certa percentuale di valori estremi da entrambe le estremità della distribuzione (ad esempio l’80 per cento intermedio).
Lo scarto medio
Lo scarto medio è una misura di variabilità che si basa sulla differenza dei singoli dati dalla loro media. Se si calcolasse la media sommando le differenze positive e negative fra i singoli dati e la media aritmetica, il risultato sarebbe sempre zero. Per questo motivo si sommano i valori assoluti delle differenze:
\( SM = \frac{\Sigma|X – \mu|}{N} \)Quei “valori assoluti” pongono qualche problema di efficienza nella computazione, motivo per cui lo scarto medio non è molto usato. Esiste un altro modo per eliminare i valori negativi, ed ecco quindi che si introduce l’importante concetto di…
Varianza
La varianza è analoga allo scarto medio, poichè si basa sulle differenze fra i singoli dati dell’insieme e la loro media, ma queste differenze sono elevate al quadrato prima di essere sommate. La varianza viene indicata con il simbolo del sigma minuscolo al quadrato e la formula è:
\( \sigma^{2}=\frac{\Sigma(X – \mu)^{2}}{N} \\ \\ \)R ha la funzione var() per il calcolo della varianza, ma computa (n-1) al denominatore. Per avere il valore della varianza per N come denominatore, possiamo allora scrivere una funzione:
varpopol <- function(variabile){var(variabile)*(1-1/length(variabile))}
In generale, risulta difficile interpretare il significato del valore di una varianza perchè le unità in cui è espresso non sono le medesime in cui sono espresse le osservazioni dell'insieme di dati.
Per questo motivo è stato introdotto lo scarto quadratico medio.
Lo scarto quadratico medio (o deviazione standard): la più usata delle misure di variabilità.
Lo scarto quadratico medio non è altro che la radice quadrata della varianza:
\( \sigma = \sqrt{\frac{\Sigma(X - \mu)^{2}}{N}} \\ \\ \)Lo scarto quadratico medio è di fondamentale utilità in statistica, particolarmente (come vedremo) in unione alla distribuzione normale di probabilità.
Nel caso di dati raggruppati si considera che il valore centrale di ciascuna classe rappresenti tutte le misurazioni comprese in quella classe. Si avrà dunque per la varianza la formula:
\( \sigma^{2}=\frac{\Sigma f(X - \mu)^{2}}{N} \\ \\ \)e per lo scarto quadratico medio:
\( \sigma = \sqrt{\frac{\Sigma f(X - \mu)^{2}}{N}} \\ \\ \)In R, la funzione per computare la deviazione standard è sd().
R tuttavia usa (n-1) al denominatore. Quindi, se vogliamo il valore della deviazione standard per una popolazione (quindi con n al denominatore) possiamo definire un'apposita funzione:
sdpopol <- function(variabile){sqrt(sum((variabile - mean(variabile))^2)/(length(variabile)))}
Il coefficiente di variazione
Il coefficiente di variazione indica la grandezza relativa dello scarto quadratico medio rispetto alla media della distribuzione delle misurazioni.
E' utilissimo per raffrontare fenomeni espressi con differenti unità di misura, poichè il CV è un numero "puro", indipendente dall'unità di misura impiegata:
Come sempre in R, esiste una funzione ad hoc : possiamo usare cv(), in questo caso definita in una libreria esterna, labstatR. L'uso è banale:
library(labstatR) dati <- c(24,17,21,23,15,30,24,21,24,19,25,28,22,20,14,19, 26,29,23,25,24,18,27,21); cv(dati); [1] 0.1817708
possiamo però anche calcolare il valore molto semplicemente senza ricorrere a librerie esterne:
dati <- c(24,17,21,23,15,30,24,21,24,19,25,28,22,20,14,19, 26,29,23,25,24,18,27,21);
sdpopol <- function(variabile){sqrt(sum((variabile - mean(variabile))^2)/(length(variabile)))}
cvdati=sdpopol(dati)/mean(dati);
cvdati;
[1] 0.1817708
La forma di una distribuzione
Le distribuzioni di frequenza possono assumere le forme più varie. Fra tutte, quella di gran lunga più importante in statistica è la distribuzione normale, o distribuzione a campana, o ancora gaussiana.
In una distribuzione normale, i dati sono ripartiti in maniera simmetrica rispetto alla media.
In maniera molto semplice, per descrivere la forma della distribuzione basta confrontare la media con la mediana: se sono uguali, la distribuzione è simmetrica. Se la media è maggiore della mediana, avremo un'asimmetria positiva (con una "coda" più lunga a destra), se la media è minore della mediana l'asimmetria risulterà negativa (con la "coda" più lunga sulla sinistra).
La più nota formula per il calcolo dell'asimmetria di una distribuzione è quella per calcolare il coefficiente di asimmetria di Pearson:
\( Asimmetria = \frac{3(\mu - med)}{\sigma} \\ \\ \)Una distribuzione perfettamente simmetrica presenta un valore di asimmetria pari a 0. Una distribuzione asimmetrica a destra (positiva) presenta un valore positivo, mentre una distribuzione asimmetrica sinistra avrà un valore negativo.
In genere i valori di asimmetria cadono tra -3 e 3 e il fatto che al denominatore compaia la deviazione standard rende il valore indipendente dall'unità di misura.
Come calcolare l'indice di asimmetria in R ?
Il modo più semplice è quello di usare una libreria che ci metta a disposizione le funzioni che ci servono "belle e pronte"...
library (moments) dati <- c(24,17,21,23,15,30,24,21,24,19,25,28,22,20,14,19, 26,29,23,25,24,18,27,21); skewness(dati); [1] -0.1918578
la libreria "moments" fa al caso nostro. Vediamo però come calcolare l'indice anche senza fare ricorso ad una libreria. E' molto semplice.
Il primo passo è quello di ricordare che R utilizza n-1 al denominatore della varianza.
Noi però stiamo ragionando di una popolazione, dunque con n al denominatore. Dunque, andiamo a definire una funzione che ci consenta di ottenere il valore che ci serve:
varpopol <- function(variabile){var(variabile)*(1-1/length(variabile))}
a questo punto possiamo calcolare il valore dell'indice di asimmetria:
dati <- c(24,17,21,23,15,30,24,21,24,19,25,28,22,20,14,19, 26,29,23,25,24,18,27,21);
varpopol <- function(variabile){var(variabile)*(1-1/length(variabile))}
zeta=(dati-mean(dati))/sqrt(varpopol(dati));
skew=mean(zeta^3);
skew;
[1] -0.1918578
La curtosi
La curtosi è il grado di altezza raggiunto da una curva di distribuzione, in relazione alla distribuzione normale.
Abbiamo 3 casi:
- una curva alta. che viene detta leptocurtica e che risulta molto concentrata intorno alla sua media
- una curva normale, detta mesocurtica
- una curva bassa e piatta, che viene definita platicurtica, poco concentrata intorno alla sua media
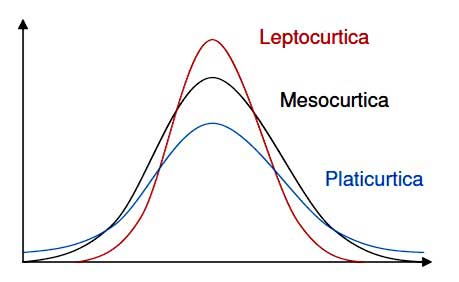
Si può misurare la curtosi dividendo il quarto momento per lo scarto quadratico medio elevato alla quarta potenza. Difficile? Più a dirsi che a calcolarsi.
Ecco la formula:
La curtosi di una curva mesocurtica ha un valore di 3. Ovviamente, un coefficiente di curtosi <3 indica una curva platicurtica, un valore >3 leptocurtica.
Come per il valore dell'indice di asimmetria, la libreria "moments" ci fornisce una comoda funzione già pronta:
library (moments) dati <- c(24,17,21,23,15,30,24,21,24,19,25,28,22,20,14,19, 26,29,23,25,24,18,27,21); kurtosis(dati); [1] 2.480035
Ma a noi non dispiace di calcolarcelo "in proprio":
dati <- c(24,17,21,23,15,30,24,21,24,19,25,28,22,20,14,19, 26,29,23,25,24,18,27,21);
varpopol <- function(variabile){var(variabile)*(1-1/length(variabile))}
zeta=(dati-mean(dati))/sqrt(varpopol(dati));
curtosi=mean(zeta^4);
curtosi;
[1] 2.480035