
In everyday life, we often have to make decisions based on incomplete information.
We may need to decide, for instance, whether a certain educational procedure is more effective than another, whether a new drug has genuinely positive effects on the course of a disease, and so on.
Hypothesis testing is a statistical procedure that allows us to pose a question on the basis of sample information, in order to reach a statistically significant decision.
In clearer and more direct terms: is my experimental finding due to chance? Hypothesis testing is precisely a statistical procedure for verifying whether chance is a plausible explanation of an experimental result.
What We’ll Cover
- A Premise: Probability vs Inference
- Statistical Hypotheses
- Type I and Type II Errors
- One or Two Tails?
- Step-by-Step Summary
- A Worked Example
- Writing a Z-Test Function in R
- The Probability of a Type II Error
- Statistical Power
- Determining the Required Sample Size
- What If We Don’t Know the Population Parameters?
- Further Reading
A Premise…
We need to understand the difference between probability and inference.
- If we know the population parameters and want to know the probability of obtaining a particular result, we are in the realm of probability.
- If from a sample we try to infer the population values, we are in the territory of inference.
Statistical Hypotheses
In hypothesis testing we always have two hypotheses to “weigh up.” The status quo is called the null hypothesis and is denoted H0.
What we do is test the null hypothesis against an alternative hypothesis, denoted Ha.
N.B. In general, the alternative hypothesis is the one we believe in!
We then choose a significance level or alpha level, α. The common standard is α = 0.05, i.e. a 95% significance level. Based on the alpha level we can determine one or more critical regions.
If the value we obtain from our test falls in a critical region, we reject the null hypothesis in favour of the alternative hypothesis.
A simple graphical example. Suppose we set up a test where the alternative hypothesis is that the mean is greater than the null hypothesis mean. This is a case with a single critical region, to the right of the α value. To reject the null hypothesis, our test value must fall in the shaded area:
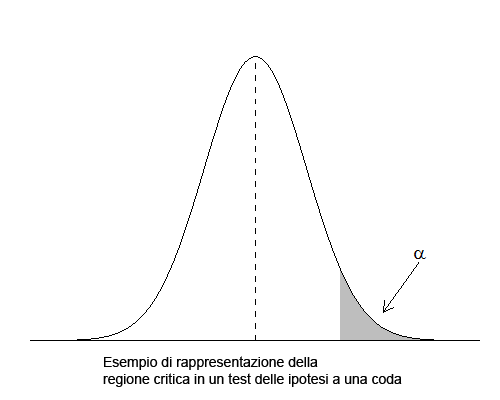
Type I and Type II Errors
The result we reach, of course, does not constitute a certainty.
The significance level of the test (in our first example, 95%) tells us the probability of committing a Type I error—that is, of erroneously rejecting the null hypothesis, which was true, and accepting the alternative hypothesis.
As we can see, we can determine the significance level of our test—that is, we can set the maximum probability with which we accept the risk of a Type I error.
If instead we accept the null hypothesis as valid when it should have been rejected because it was false, we commit a Type II error.
The clearest way I have found to explain the concept is this:

Calculating the probability of a Type II error is not as straightforward as for a Type I error, and we will address it in a somewhat simplified manner further on.
One or Two Tails? That Is the Question…
The test can be one-tailed, for example if the alternative hypothesis is that a mean is greater than the null hypothesis mean:
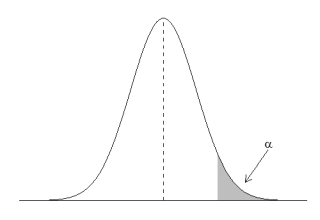
Or it can be two-tailed (if the alternative hypothesis is that the mean I hypothesise is different from the null hypothesis).
In a two-tailed test we will have 2 critical regions at the two extremes of the curve, each representing a level of α/2:
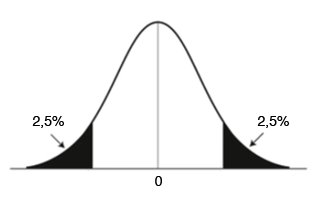
Step-by-Step Summary
- State the null hypothesis and the alternative hypothesis.
- Set the significance level (alpha level).
- Which distribution to use: normal or t?
- Collect and analyse the data.
- Draw conclusions.
We must ask ourselves a fundamental question: which distribution should we use?
The answer can be found by looking at sigma (the standard deviation) and the sample size. We ask ourselves:
Do we know the population sigma? (in practice, a rather rare case…) Do we have a sufficiently large sample (n > 30)?
If the answer is YES, then we use the normal distribution (and compute the Z-score).
If the answer is NO—that is, if we do not know the population sigma (or if we are working with small samples)—then we use the t distribution or Student’s distribution.
N.B. As the sample grows larger, the t distribution approximates the normal more and more closely…
A Worked Example
We want to conduct a hypothesis test in a situation where we know the population sigma. Let us follow our steps.
1 — State the null and alternative hypotheses
If:
\(H_{0}: \mu = x \\
H_{a}: \mu \neq x \\
\)
then we have a two-tailed test. We will have two critical regions to consider.
If instead:
\(H_{0}: \mu = x \\
H_{a}: \mu > x \\
\)
then the test is one-tailed.
2 — Set the significance level (alpha level)
Let us choose the most typical case, a 95% significance level, so:
\(\alpha = 0.05 \\
\)
3 and 4 — Choose the distribution and Collect and analyse the data
Suppose we have collected the data. We now ask which distribution we should use for our test. The question is always the same: do we know the population sigma?
In our example, let us say yes—so we use the normal distribution.
We compute the standard error and the Z-score:
\(\sigma_{\bar{x}}= \frac{\sigma}{\sqrt{n}} \\
\)
Now we can find Z:
\(Z = \frac{\bar{x} – \mu}{\sigma_{\bar{x}}} \\
\)
5 — (Finally) Draw conclusions
Suppose the test is:
\(H_{0}: \mu = x \\
H_{a}: \mu \neq x \\
\)
So it is two-tailed. The chosen significance level is 95%, so we look up 2.5% (5%/2) on the table, and find the value 1.96.
N.B. We could have used R with the function:
qnorm(0.025)Whichever tool we use, the value we find will be (rounded) 1.96.
Therefore -1.96 and +1.96 are the critical values.
If our Z-score turns out to be, say, 2.50, we immediately notice that the value falls within the critical region. We can then reject the null hypothesis and accept the alternative.
Two quick tips:
1) Always draw the graph. It will help enormously in avoiding mistakes.
2) The most commonly used significance levels are 5% and 1%. The critical values for one-tailed and two-tailed tests that we will encounter most often are:
| Significance level | One-tailed | Two-tailed |
|---|---|---|
| 5% (alpha 0.05) | 1.65 (+ or -) | ± 1.96 |
| 1% (alpha 0.01) | 2.33 (+ or -) | ± 2.58 |
Making Life Easier: Writing a Function in R
Let us simplify things and prepare a function in R, which we will call z.test:
z.test <- function(x, mu, popvar) {
one.tail.p <- NULL
z.score <- round((mean(x) - mu) / (popvar / sqrt(length(x))), 3)
one.tail.p <- round(pnorm(abs(z.score), lower.tail = FALSE), 3)
cat("z =", z.score, "\n",
"one-tailed probability =", one.tail.p, "\n",
"two-tailed probability =", 2 * one.tail.p)
}The Probability of a Type II Error
As we have seen, the probability of committing a Type I error is set in advance in our test by choosing the significance level, alpha.
Let us suppose, for example, that a certain measurement related to a hypothesised mean value has as its null hypothesis a value equal to or greater than 260. Our alternative hypothesis is therefore that this mean value is less than 260. We further establish that a value of 240 or less would constitute an important deviation. In our example, the significance level is set at 95% (alpha = 0.05), the sample consists of 36 observations, and the standard deviation is 43.
\(\bar{X}_{critical}=\mu_0 + z\sigma_{\bar{x}}= 260+(-1.65)(7.17)=248.17 \\
\)
where:
\(\sigma_{\bar{x}}=\frac{\sigma}{\sqrt{n}}=\frac{43}{\sqrt{36}}=\frac{43}{6}=7.17 \\ \\
\)
As we have repeated several times, the probability of a Type I error equals the significance level, thus 0.05 (5%).
The probability of a Type II error is the probability that the sample mean is ≥ 248.17.
If we conduct our measurement and find a mean of 240:
\(z=\frac{\bar{X}_{critical}-\mu_1}{\sigma_{\bar{x}}}= \frac{248.17-240}{7.17}=\frac{8.17}{7.17}=1.14 \\ \\
\)
Therefore: P(Type II error) = P(z ≥ 1.14) = 0.1271, that is, approximately 0.13, or 13%.
If we keep the significance level and sample size constant but move the specific alternative mean value further from the null hypothesis value, then the probability of a Type II error decreases; conversely, the probability increases if the alternative value is set closer to the null hypothesis value.
Statistical Power
In hypothesis testing, the notion of power refers to the probability of rejecting the null hypothesis, given a specific alternative value of the parameter (in our example, the population mean).
Denoting the probability of a Type II error by β, the power of the test is always 1 - β.
A graph constructed to represent the various power levels given the various alternative mean values is called a power curve.
Returning to our example, with the alternative mean value of 240:
β = P(Type II error) = 0.13
Power = 1 - β = 1 - 0.13 = 0.87
This is the probability of correctly rejecting the null hypothesis when μ = 240.
Determining the Required Sample Size for a Mean Test
Before drawing a sample, we can determine the required sample size by specifying:
- The hypothesised value of the mean
- The alternative value of the mean, such that its difference from the null hypothesis value is considered important
- The significance level of the test
- The accepted probability of a Type II error
- The population standard deviation, sigma
The formula is:
\(n=\frac{(z_0-z_1)^2\sigma^2}{(\mu_1-\mu_0)^2} \\ \\
\)
In our example, we set as acceptable levels: Type I error: 0.05; Type II error: 0.10; sigma = 43.
\(n=\frac{(z_0-z_1)^2\sigma^2}{(\mu_1-\mu_0)^2}= \frac{(-1.65-1.28)^2(43)^2}{(240-260)^2}= \frac{8.5849 \times 1849}{400}= 39.68 \approx 40 \\
\)
The value we were looking for is (approximately) 40.
At the End of All This... What If We Don't Know the Population Parameters?
If we do not know the population sigma, or if we are working with small samples (fewer than 30 values), we use the t distribution or Student's distribution. But that will be the subject of the next article...
You might also like
- Guide to Statistical Tests for A/B Analysis
- Confidence Intervals: What They Are, How to Calculate Them (and What They Do NOT Mean)
- The Chi-Square Test
Further Reading
For a thorough treatment of hypothesis testing, confidence intervals, and the logic of statistical inference, Statistica by Newbold, Carlson and Thorne is one of the most complete references available. Its step-by-step approach to hypothesis testing—from formulating hypotheses through to interpreting p-values—makes it an invaluable companion for anyone working with inferential statistics.